JUMP TO TOPIC
The Standard Deviation – Explanation & Examples
 The definition of the standard deviation is:
The definition of the standard deviation is:
“The standard deviation is a measure of the dispersion of a set of numerical values relative to their mean.”
In this topic, we will discuss the standard deviation from the following aspects:
- What is the standard deviation?
- How to calculate the standard deviation?
- Standard deviation formula.
- The role of the standard deviation.
- Practice questions.
- Answer key.
What is the standard deviation?
The standard deviation is a measure of the dispersion of a set of numerical values from their mean.
We calculate the standard deviation as the square root of the variance. The variance is the mean or average of the squared differences from the mean.
The variance has the squared unit of the numerical data due to squared differences in its calculation, so it is difficult to interpret.
Alternatively, the standard deviation has the same unit of the numerical data and is easier to interpret.
A large standard deviation indicates that your data numbers are far from the mean and far from each other. In contrast, a small standard deviation indicates that numbers in your data are more clustered around their mean.
A zero standard deviation indicates that all numbers within your data are identical.
– Example
Suppose you have two sets of 3 numbers (1,2,3) and (1,2,10). You see that the second set is more spread (more varied) than the first set.
You can see that from the following dot plot.
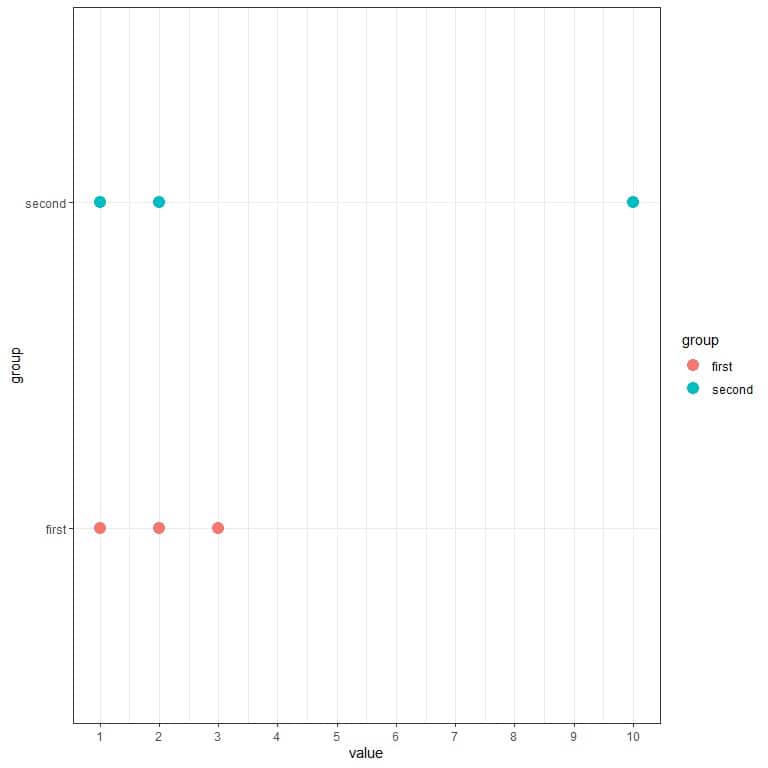
We see that the blue dots (second group) are more spread out than the red dots (first group).
Suppose we calculate the standard deviation for the first group. In that case, it is 1, while the standard deviation for the second group is 4.9. Therefore, the second group is more spread (more varied) than the first group.
How to calculate the standard deviation?
We will go through several examples, from simple to more complex ones.
– Example 1
What is the standard deviation of the numbers, 1,2,3?
1. Add up all of the numbers:
1+2+3 = 6.
2. Count the numbers of items in your data. In this data, there are 3 items.
3. Divide the number you found in step 1 by the number you found in step 2.
The mean = 6/3 = 2.
4. In a table, subtract the mean from each value of your data.
value | value-mean |
1 | -1 |
2 | 0 |
3 | 1 |
You have a table of 2 columns, one for the data values and the other column for subtracting the mean (2) from each value.
5. Add another column for the squared differences you found in Step 4.
value | value-mean | squared difference |
1 | -1 | 1 |
2 | 0 | 0 |
3 | 1 | 1 |
6. Add up all of the squared differences you found in Step 5.
1+0+1 = 2.
7. Divide the number you get in step 6 by sample size-1 to get the variance. We have 3 numbers, so the sample size is 3.
The variance = 2/(3-1) = 1.
8. Take the square root of the variance to get the standard deviation.
The standard deviation = √1 = 1.
– Example 2
What is the standard deviation of the numbers, 1,2,10?
1. Add up all of the numbers:
1+2+10 = 13.
2. Count the numbers of items in your data. In this data, there are 3 items.
3. Divide the number you found in step 1 by the number you found in step 2.
The mean = 13/3 = 4.33.
4. In a table, subtract the mean from each value of your sample.
value | value-mean |
1 | -3.33 |
2 | -2.33 |
10 | 5.67 |
We have 2 columns, one for the data values and the other column for subtracting the mean (4.33) from each value.
5. Add another column for the squared differences you found in Step 4.
value | value-mean | squared difference |
1 | -3.33 | 11.09 |
2 | -2.33 | 5.43 |
10 | 5.67 | 32.15 |
6. Add up all of the squared differences you found in Step 5.
11.09 + 5.43 + 32.15 = 48.67.
7. Divide the number you get in step 6 by sample size-1 to get the variance. We have 3 numbers, so the sample size is 3.
The variance = 48.67/(3-1) = 24.335.
8. Take the square root of the variance to get the standard deviation.
The standard deviation = √24.335 = 4.9.
– Example 3
The following is the weight (in kg) of 30 smoking individuals and 30 never-smoking individuals. What is the standard deviation of each sample?
smoker | never smoker |
70.0 | 64.0 |
43.5 | 67.0 |
66.0 | 68.0 |
60.0 | 79.2 |
88.0 | 45.8 |
75.0 | 65.0 |
76.0 | 69.0 |
80.0 | 76.0 |
50.4 | 69.0 |
67.0 | 77.0 |
72.4 | 63.4 |
73.0 | 65.5 |
85.0 | 55.0 |
67.0 | 58.0 |
89.0 | 84.5 |
76.0 | 94.0 |
66.0 | 68.0 |
87.5 | 60.3 |
79.0 | 98.0 |
59.0 | 51.0 |
80.2 | 53.0 |
64.0 | 53.0 |
65.2 | 70.0 |
56.3 | 77.0 |
82.0 | 94.0 |
60.8 | 75.0 |
72.0 | 73.0 |
83.0 | 71.0 |
64.0 | 57.0 |
51.0 | 56.6 |
For the smoker group:
1. Add up all of the weights:
Sum = 2108.3.
2. Count the numbers of items in your group. In this sample, there are 30 items or individuals.
3. Divide the number you found in step 1 by the number you found in step 2.
The sample mean = 2108.3/30 = 70.28 kg.
4. In a table, subtract the mean from each value of your sample.
smoker | weight-mean |
70.0 | -0.28 |
43.5 | -26.78 |
66.0 | -4.28 |
60.0 | -10.28 |
88.0 | 17.72 |
75.0 | 4.72 |
76.0 | 5.72 |
80.0 | 9.72 |
50.4 | -19.88 |
67.0 | -3.28 |
72.4 | 2.12 |
73.0 | 2.72 |
85.0 | 14.72 |
67.0 | -3.28 |
89.0 | 18.72 |
76.0 | 5.72 |
66.0 | -4.28 |
87.5 | 17.22 |
79.0 | 8.72 |
59.0 | -11.28 |
80.2 | 9.92 |
64.0 | -6.28 |
65.2 | -5.08 |
56.3 | -13.98 |
82.0 | 11.72 |
60.8 | -9.48 |
72.0 | 1.72 |
83.0 | 12.72 |
64.0 | -6.28 |
51.0 | -19.28 |
5. Add another column for the squared differences you found in Step 4.
smoker | weight-mean | squared difference |
70.0 | -0.28 | 0.08 |
43.5 | -26.78 | 717.17 |
66.0 | -4.28 | 18.32 |
60.0 | -10.28 | 105.68 |
88.0 | 17.72 | 314.00 |
75.0 | 4.72 | 22.28 |
76.0 | 5.72 | 32.72 |
80.0 | 9.72 | 94.48 |
50.4 | -19.88 | 395.21 |
67.0 | -3.28 | 10.76 |
72.4 | 2.12 | 4.49 |
73.0 | 2.72 | 7.40 |
85.0 | 14.72 | 216.68 |
67.0 | -3.28 | 10.76 |
89.0 | 18.72 | 350.44 |
76.0 | 5.72 | 32.72 |
66.0 | -4.28 | 18.32 |
87.5 | 17.22 | 296.53 |
79.0 | 8.72 | 76.04 |
59.0 | -11.28 | 127.24 |
80.2 | 9.92 | 98.41 |
64.0 | -6.28 | 39.44 |
65.2 | -5.08 | 25.81 |
56.3 | -13.98 | 195.44 |
82.0 | 11.72 | 137.36 |
60.8 | -9.48 | 89.87 |
72.0 | 1.72 | 2.96 |
83.0 | 12.72 | 161.80 |
64.0 | -6.28 | 39.44 |
51.0 | -19.28 | 371.72 |
6. Add up all of the squared differences you found in Step 5.
Sum = 4013.57.
7. Divide the number you get in step 6 by sample size-1 to get the variance. We have 30 numbers, so the sample size is 30.
The variance = 4013.57/(30-1) = 138.399 kg^2.
8. Take the square root of the variance to get the standard deviation.
The standard deviation = √138.399 = 11.76 kg.
Note that the standard deviation has the same unit as the original data (kg).
For the never smoker group:
1. Add up all of the weights:
Sum = 2057.3.
2. Count the numbers of items in your group. In this sample, there are 30 items or individuals.
3. Divide the number you found in step 1 by the number you found in step 2.
The sample mean = 2057.3/30 = 68.58.
4. In a table, subtract the mean from each value of your sample.
never smoker | weight-mean |
64.0 | -4.58 |
67.0 | -1.58 |
68.0 | -0.58 |
79.2 | 10.62 |
45.8 | -22.78 |
65.0 | -3.58 |
69.0 | 0.42 |
76.0 | 7.42 |
69.0 | 0.42 |
77.0 | 8.42 |
63.4 | -5.18 |
65.5 | -3.08 |
55.0 | -13.58 |
58.0 | -10.58 |
84.5 | 15.92 |
94.0 | 25.42 |
68.0 | -0.58 |
60.3 | -8.28 |
98.0 | 29.42 |
51.0 | -17.58 |
53.0 | -15.58 |
53.0 | -15.58 |
70.0 | 1.42 |
77.0 | 8.42 |
94.0 | 25.42 |
75.0 | 6.42 |
73.0 | 4.42 |
71.0 | 2.42 |
57.0 | -11.58 |
56.6 | -11.98 |
5. Add another column for the squared differences you found in Step 4.
never smoker | weight-mean | squared difference |
64.0 | -4.58 | 20.98 |
67.0 | -1.58 | 2.50 |
68.0 | -0.58 | 0.34 |
79.2 | 10.62 | 112.78 |
45.8 | -22.78 | 518.93 |
65.0 | -3.58 | 12.82 |
69.0 | 0.42 | 0.18 |
76.0 | 7.42 | 55.06 |
69.0 | 0.42 | 0.18 |
77.0 | 8.42 | 70.90 |
63.4 | -5.18 | 26.83 |
65.5 | -3.08 | 9.49 |
55.0 | -13.58 | 184.42 |
58.0 | -10.58 | 111.94 |
84.5 | 15.92 | 253.45 |
94.0 | 25.42 | 646.18 |
68.0 | -0.58 | 0.34 |
60.3 | -8.28 | 68.56 |
98.0 | 29.42 | 865.54 |
51.0 | -17.58 | 309.06 |
53.0 | -15.58 | 242.74 |
53.0 | -15.58 | 242.74 |
70.0 | 1.42 | 2.02 |
77.0 | 8.42 | 70.90 |
94.0 | 25.42 | 646.18 |
75.0 | 6.42 | 41.22 |
73.0 | 4.42 | 19.54 |
71.0 | 2.42 | 5.86 |
57.0 | -11.58 | 134.10 |
56.6 | -11.98 | 143.52 |
6. Add up all of the squared differences you found in Step 5.
Sum = 4819.3.
7. Divide the number you get in step 6 by sample size-1 to get the variance. We have 30 numbers, so the sample size is 30.
The variance = 4819.3/(30-1) = 166.18 kg^2.
8. Take the square root of the variance to get the standard deviation.
The standard deviation = √166.18 = 12.89 kg.
The never smoker weights are more variable than smoker weights. It is also evident from the following dot plot.
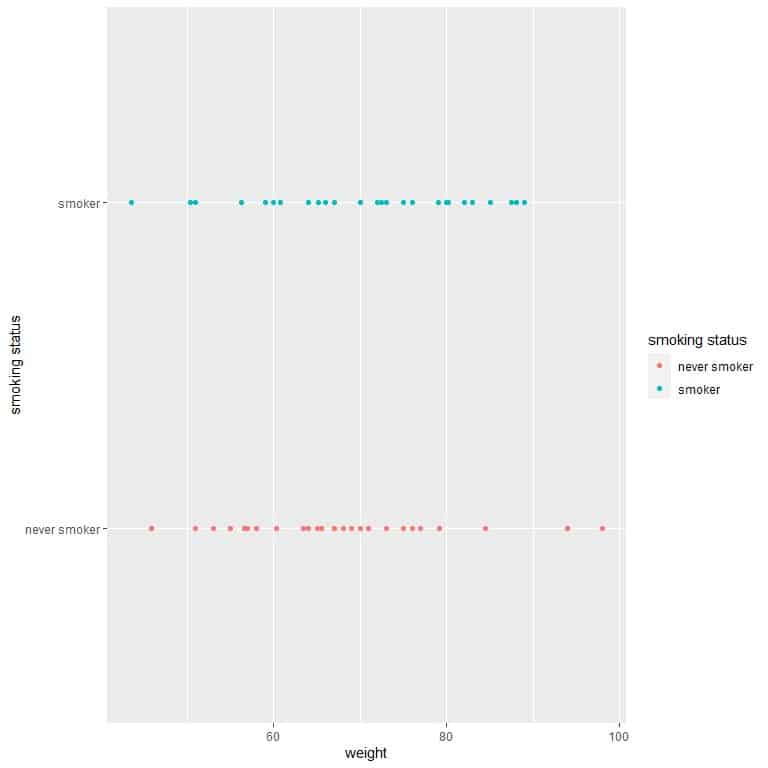
We see that the never smoker weights are more spread out than the smoker weights.
– Example 4
The following is a table for the weights of diamonds produced from 2 different machines. Which machine is better?
Note less variable weights means a more precise machine which is a good criterion. If the variability is high, the machine will produce many diamonds whose weights are out of the desired limits.
machine_1 | machine_2 |
0.23 | 0.42 |
0.21 | 0.70 |
0.23 | 0.86 |
0.29 | 0.70 |
0.31 | 0.71 |
0.24 | 0.78 |
0.24 | 0.70 |
0.26 | 0.70 |
0.22 | 0.96 |
0.23 | 0.73 |
0.30 | 0.80 |
0.23 | 0.75 |
0.22 | 0.75 |
0.31 | 0.74 |
0.20 | 0.75 |
0.32 | 0.80 |
0.30 | 0.75 |
0.30 | 0.80 |
0.30 | 0.74 |
0.30 | 0.81 |
0.30 | 0.59 |
0.23 | 0.80 |
0.23 | 0.74 |
0.31 | 0.90 |
0.31 | 0.74 |
0.23 | 0.73 |
0.24 | 0.73 |
0.30 | 0.80 |
0.23 | 0.71 |
0.23 | 0.70 |
0.23 | 0.80 |
0.23 | 0.71 |
0.23 | 0.74 |
0.23 | 0.70 |
0.23 | 0.70 |
For machine_1:
1. Add up all of the numbers:
Sum = 9.
2. Count the numbers of items in your sample. In this sample, there are 35 items.
3. Divide the number you found in step 1 by the number you found in step 2.
The sample mean = 9/35 = 0.2571.
4. In a table, subtract the mean from each value of your sample.
machine_1 | weight-mean |
0.23 | -0.0271 |
0.21 | -0.0471 |
0.23 | -0.0271 |
0.29 | 0.0329 |
0.31 | 0.0529 |
0.24 | -0.0171 |
0.24 | -0.0171 |
0.26 | 0.0029 |
0.22 | -0.0371 |
0.23 | -0.0271 |
0.30 | 0.0429 |
0.23 | -0.0271 |
0.22 | -0.0371 |
0.31 | 0.0529 |
0.20 | -0.0571 |
0.32 | 0.0629 |
0.30 | 0.0429 |
0.30 | 0.0429 |
0.30 | 0.0429 |
0.30 | 0.0429 |
0.30 | 0.0429 |
0.23 | -0.0271 |
0.23 | -0.0271 |
0.31 | 0.0529 |
0.31 | 0.0529 |
0.23 | -0.0271 |
0.24 | -0.0171 |
0.30 | 0.0429 |
0.23 | -0.0271 |
0.23 | -0.0271 |
0.23 | -0.0271 |
0.23 | -0.0271 |
0.23 | -0.0271 |
0.23 | -0.0271 |
0.23 | -0.0271 |
5. Add another column for the squared differences you found in Step 4.
machine_1 | weight-mean | squared difference |
0.23 | -0.0271 | 0.0007 |
0.21 | -0.0471 | 0.0022 |
0.23 | -0.0271 | 0.0007 |
0.29 | 0.0329 | 0.0011 |
0.31 | 0.0529 | 0.0028 |
0.24 | -0.0171 | 0.0003 |
0.24 | -0.0171 | 0.0003 |
0.26 | 0.0029 | 0.0000 |
0.22 | -0.0371 | 0.0014 |
0.23 | -0.0271 | 0.0007 |
0.30 | 0.0429 | 0.0018 |
0.23 | -0.0271 | 0.0007 |
0.22 | -0.0371 | 0.0014 |
0.31 | 0.0529 | 0.0028 |
0.20 | -0.0571 | 0.0033 |
0.32 | 0.0629 | 0.0040 |
0.30 | 0.0429 | 0.0018 |
0.30 | 0.0429 | 0.0018 |
0.30 | 0.0429 | 0.0018 |
0.30 | 0.0429 | 0.0018 |
0.30 | 0.0429 | 0.0018 |
0.23 | -0.0271 | 0.0007 |
0.23 | -0.0271 | 0.0007 |
0.31 | 0.0529 | 0.0028 |
0.31 | 0.0529 | 0.0028 |
0.23 | -0.0271 | 0.0007 |
0.24 | -0.0171 | 0.0003 |
0.30 | 0.0429 | 0.0018 |
0.23 | -0.0271 | 0.0007 |
0.23 | -0.0271 | 0.0007 |
0.23 | -0.0271 | 0.0007 |
0.23 | -0.0271 | 0.0007 |
0.23 | -0.0271 | 0.0007 |
0.23 | -0.0271 | 0.0007 |
0.23 | -0.0271 | 0.0007 |
6. Add up all of the squared differences you found in Step 5.
Sum = 0.0479.
7. Divide the number you get in step 6 by sample size-1 to get the variance. Our sample size is 35.
The variance = 0.0479/(35-1) = 0.0014 grams^2.
8. Take the square root of the variance to get the standard deviation.
The standard deviation = √0.0014 = 0.037 grams.
For machine_2:
1. Add up all of the numbers:
Sum = 26.04.
2. Count the numbers of items in your sample. In this sample, there are 35 items.
3. Divide the number you found in step 1 by the number you found in step 2.
The sample mean = 26.04/35 = 0.744.
4. In a table, subtract the mean from each value of your sample.
machine_2 | weight-mean |
0.42 | -0.324 |
0.70 | -0.044 |
0.86 | 0.116 |
0.70 | -0.044 |
0.71 | -0.034 |
0.78 | 0.036 |
0.70 | -0.044 |
0.70 | -0.044 |
0.96 | 0.216 |
0.73 | -0.014 |
0.80 | 0.056 |
0.75 | 0.006 |
0.75 | 0.006 |
0.74 | -0.004 |
0.75 | 0.006 |
0.80 | 0.056 |
0.75 | 0.006 |
0.80 | 0.056 |
0.74 | -0.004 |
0.81 | 0.066 |
0.59 | -0.154 |
0.80 | 0.056 |
0.74 | -0.004 |
0.90 | 0.156 |
0.74 | -0.004 |
0.73 | -0.014 |
0.73 | -0.014 |
0.80 | 0.056 |
0.71 | -0.034 |
0.70 | -0.044 |
0.80 | 0.056 |
0.71 | -0.034 |
0.74 | -0.004 |
0.70 | -0.044 |
0.70 | -0.044 |
5. Add another column for the squared differences you found in Step 4.
machine_2 | weight-mean | squared difference |
0.42 | -0.324 | 0.1050 |
0.70 | -0.044 | 0.0019 |
0.86 | 0.116 | 0.0135 |
0.70 | -0.044 | 0.0019 |
0.71 | -0.034 | 0.0012 |
0.78 | 0.036 | 0.0013 |
0.70 | -0.044 | 0.0019 |
0.70 | -0.044 | 0.0019 |
0.96 | 0.216 | 0.0467 |
0.73 | -0.014 | 0.0002 |
0.80 | 0.056 | 0.0031 |
0.75 | 0.006 | 0.0000 |
0.75 | 0.006 | 0.0000 |
0.74 | -0.004 | 0.0000 |
0.75 | 0.006 | 0.0000 |
0.80 | 0.056 | 0.0031 |
0.75 | 0.006 | 0.0000 |
0.80 | 0.056 | 0.0031 |
0.74 | -0.004 | 0.0000 |
0.81 | 0.066 | 0.0044 |
0.59 | -0.154 | 0.0237 |
0.80 | 0.056 | 0.0031 |
0.74 | -0.004 | 0.0000 |
0.90 | 0.156 | 0.0243 |
0.74 | -0.004 | 0.0000 |
0.73 | -0.014 | 0.0002 |
0.73 | -0.014 | 0.0002 |
0.80 | 0.056 | 0.0031 |
0.71 | -0.034 | 0.0012 |
0.70 | -0.044 | 0.0019 |
0.80 | 0.056 | 0.0031 |
0.71 | -0.034 | 0.0012 |
0.74 | -0.004 | 0.0000 |
0.70 | -0.044 | 0.0019 |
0.70 | -0.044 | 0.0019 |
6. Add up all of the squared differences you found in Step 5.
Sum = 0.255.
7. Divide the number you get in step 6 by sample size-1 to get the variance. Our sample size is 35.
The variance = 0.255/(35-1) = 0.0075 grams^2.
8. Take the square root of the variance to get the standard deviation.
The standard deviation = √0.0075 = 0.087 grams.
machine_2 weights are more variable than machine_1 weights. We can see that if we plot the data as a dot plot.
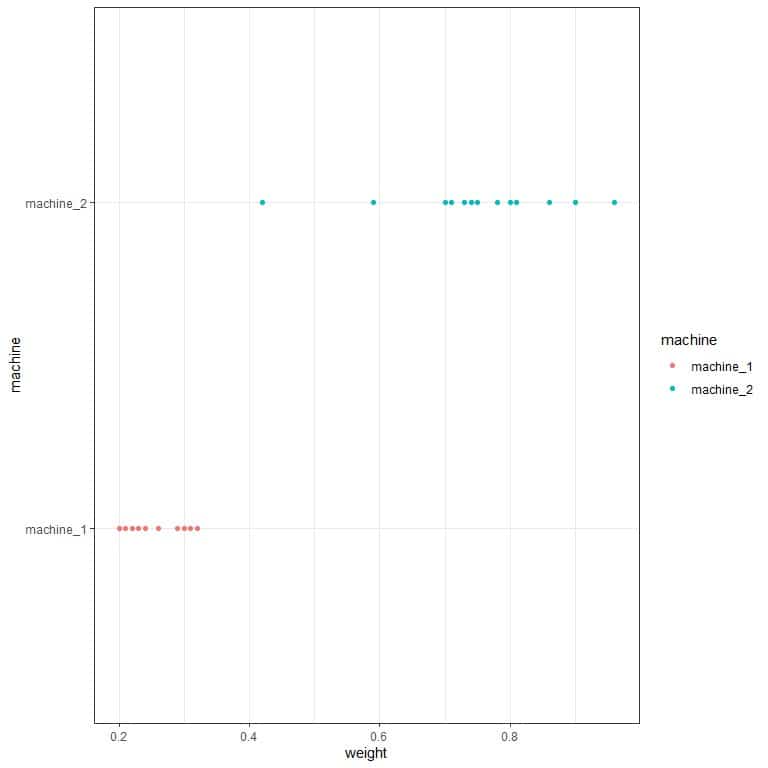
We see that machine_1 weights occupy a smaller numerical range than machine_2 weights.
Standard deviation formula
The standard deviation formula is:
s=√((∑_(i=1)^n▒( x_i-¯x )^2)/(n-1))
Where s is the standard deviation.
¯x is the sample mean.
n is the sample size.
The term:
∑_(i=1)^n▒( x_i-¯x )^2
means sum the squared difference between every element of our sample (from x_1 to x_n) and the sample mean ¯x.
Our sample element is denoted as x with a subscript to indicate its position in our sample.
In the example of diamonds’ weights for machine_1, we have 35 weights. The first weight (0.23) is denoted as x_1, the second weight (0.21) is denoted as x_2, the third weight (0.23) is denoted as x_3And the last weight (0.23) is denoted as x_35 or x_n because n = 35 in this case.
We used this formula in the above examples, where we summed the squared difference between every element of our data and the sample mean, then divided by the sample size-1 or n-1 to get the variance. Finally, we took the square root of the variance to get the standard deviation.
We divide by n-1 when calculating the variance or the standard deviation (and not by n as any average) to make the sample standard deviation a good estimator of the true population standard deviation.
However, if you have population data, you will divide by N (where N is the population size) to get the standard deviation.
Example
We have a population of more than 20,000 individuals. From the census data, the population standard deviation for the age was 17.29 years.
We take a random sample of 50 individuals from this data. The sum of squared differences from the mean was 12112.08.
If we divide by 50 (sample size), the variance will be 242.24, and the standard deviation will be 15.56.
If we divide by 49 (sample size-1), the variance will be 247.19, and the standard deviation will be 15.72.
Dividing by n-1 will make the variance and standard deviation a bit larger and prevent them from underestimating the true population variance or standard deviation.
The role of the standard deviation
The standard deviation is a summary statistic used to give information about your data or population’s spread.
In the above example of two machines, although we have only a sample of 35 diamonds from each machine, we can conclude that (with some level of certainty) that machine_2 is more variable (and so worse) than machine_1.
When some machines produce a certain product with a high standard deviation for certain criteria (like weight for diamonds), these machines need adjustment.
Standard deviation is also important in an investment where standard deviation (as a measure of spread or variability) can be used to measure risk.
Stocks prices with greater standard deviations are riskier to invest in.
Disadvantages of standard deviation as a measure of spread:
It is affected by outliers. These are the numbers that are far from the mean.
Practice questions
1. The following table is the daily closing prices (in USD) of 3 stocks from the information technology sector, Apple (AAPL), Microsoft (MSFT), and Adobe (ADBE), for some days in 2006. Which stock has the least standard deviation for the closing prices?
| Apple | Microsoft | Adobe |
2006-06-01 | 8.881429 | 22.82 | 28.72 |
2006-06-02 | 8.808572 | 22.76 | 29.00 |
2006-06-05 | 8.571428 | 22.50 | 29.47 |
2006-06-06 | 8.531428 | 22.13 | 29.84 |
2006-06-07 | 8.365714 | 22.04 | 28.82 |
2006-06-08 | 8.680000 | 22.11 | 27.85 |
2006-06-09 | 8.462857 | 21.92 | 27.99 |
2006-06-12 | 8.142858 | 21.71 | 28.84 |
2006-06-13 | 8.332857 | 21.51 | 28.98 |
2006-06-14 | 8.230000 | 21.88 | 28.57 |
2006-06-15 | 8.482857 | 22.07 | 28.96 |
2006-06-16 | 8.222857 | 22.10 | 29.12 |
2006-06-19 | 8.171429 | 22.55 | 28.78 |
2006-06-20 | 8.210000 | 22.56 | 29.53 |
2006-06-21 | 8.265715 | 23.08 | 29.88 |
2006-06-22 | 8.511429 | 22.88 | 30.79 |
2006-06-23 | 8.404285 | 22.50 | 30.60 |
2006-06-26 | 8.427143 | 22.82 | 30.69 |
2006-06-27 | 8.204286 | 22.86 | 29.94 |
2006-06-28 | 8.002857 | 23.16 | 30.06 |
2006-06-29 | 8.424286 | 23.47 | 30.40 |
2006-06-30 | 8.181429 | 23.30 | 30.36 |
2006-07-03 | 8.278571 | 23.70 | 30.64 |
2006-07-05 | 8.142858 | 23.35 | 29.86 |
2006-07-06 | 7.967143 | 23.48 | 29.59 |
2006-07-07 | 7.914286 | 23.30 | 29.42 |
2006-07-10 | 7.857143 | 23.50 | 29.26 |
2006-07-11 | 7.950000 | 23.10 | 29.55 |
2006-07-12 | 7.565714 | 22.64 | 28.56 |
2006-07-13 | 7.464286 | 22.26 | 28.10 |
2. The following is a table of the inside diameter (in mm) for piston rings produced from 3 different machines. Which machine is more precise in its production?
Note more precise means less variable.
machine_1 | machine_2 | machine_3 |
73.995 | 73.992 | 74.001 |
74.010 | 74.000 | 73.994 |
74.005 | 73.999 | 74.004 |
74.026 | 73.996 | 74.015 |
74.000 | 74.005 | 74.000 |
73.995 | 73.994 | 74.000 |
73.993 | 74.009 | 74.014 |
74.009 | 74.009 | 74.000 |
74.029 | 74.008 | 73.998 |
74.025 | 74.000 | 74.008 |
74.015 | 74.003 | 74.010 |
74.000 | 74.006 | 73.984 |
73.984 | 74.006 | 74.015 |
74.012 | 74.020 | 73.993 |
74.019 | 74.029 | 73.992 |
74.002 | 74.025 | 74.008 |
73.999 | 73.999 | 74.012 |
74.020 | 74.015 | 74.000 |
74.014 | 74.004 | 73.996 |
74.009 | 73.994 | 74.002 |
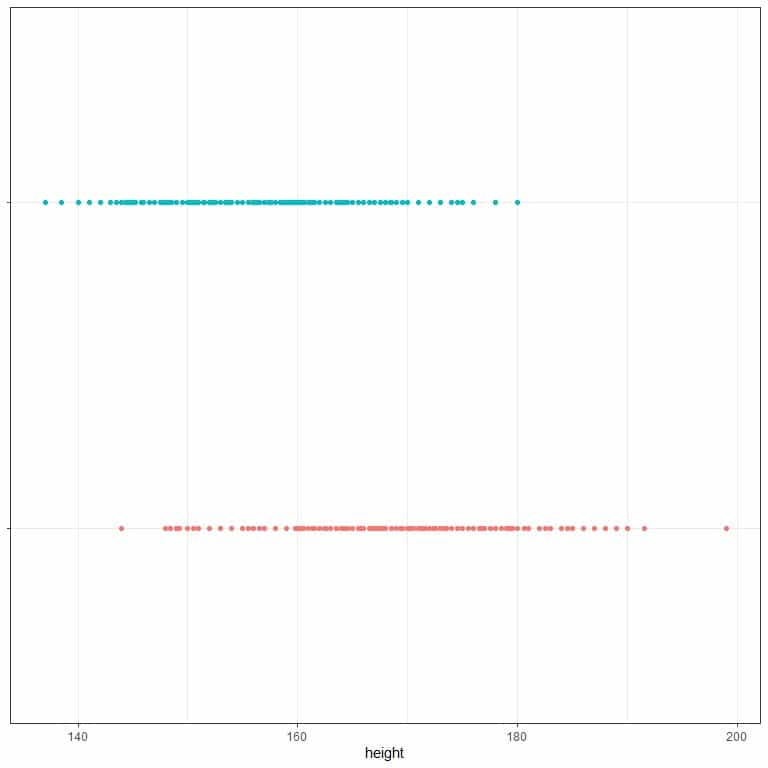
3. The following is the standard deviation for heights of females and males from a certain population. Also, dot plots for the height values. Which dots are males, and which are females?
sex | standard deviation |
Male | 7.34 |
Female | 6.41 |
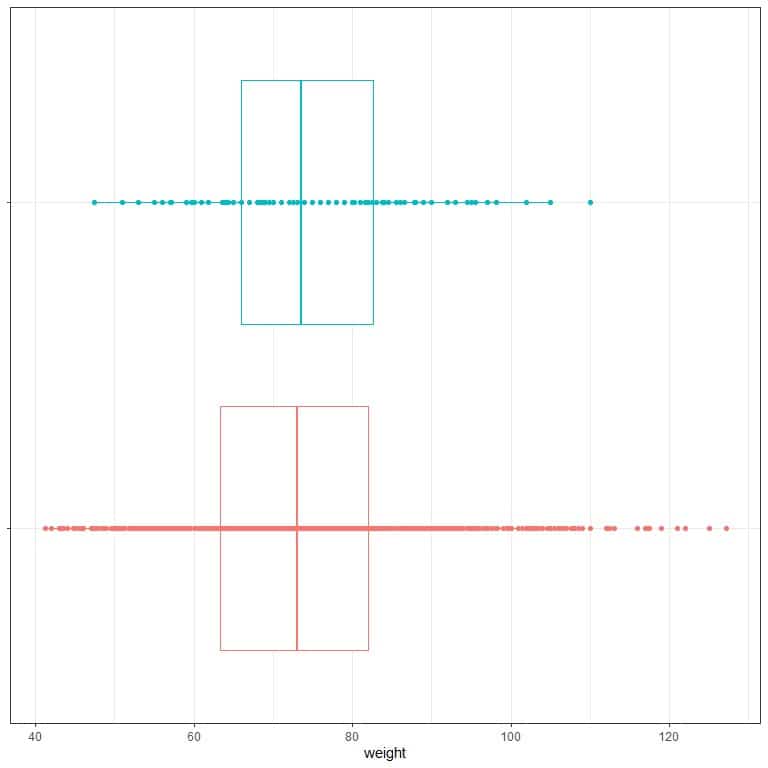
4. The following is the standard deviation for weights of individuals who had a cardiovascular event (cv) and other individuals who did not have this event from a certain population. Also, box plots and dot plots for the weight values. Which dots are individuals with cardiovascular events?
cv | standard deviation |
No | 13.68 |
Yes | 12.82 |
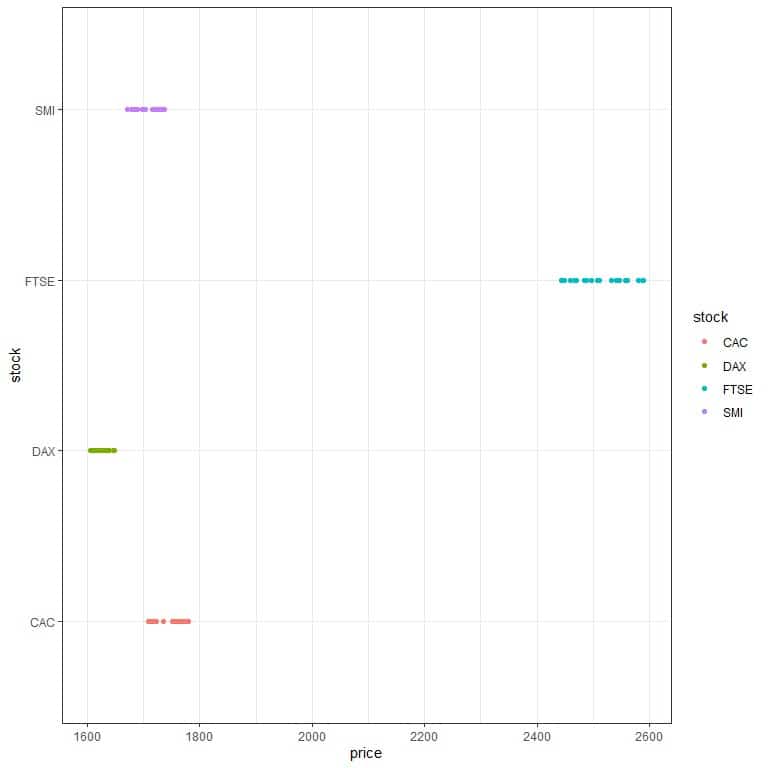
 5. The following are the daily closing prices of major European stock indices: Germany DAX (Ibis), Switzerland SMI, France CAC, and UK FTSE for some days in 1991. Which stock has the most standard deviation?
5. The following are the daily closing prices of major European stock indices: Germany DAX (Ibis), Switzerland SMI, France CAC, and UK FTSE for some days in 1991. Which stock has the most standard deviation?
DAX | SMI | CAC | FTSE |
1628.75 | 1678.1 | 1772.8 | 2443.6 |
1613.63 | 1688.5 | 1750.5 | 2460.2 |
1606.51 | 1678.6 | 1718.0 | 2448.2 |
1621.04 | 1684.1 | 1708.1 | 2470.4 |
1618.16 | 1686.6 | 1723.1 | 2484.7 |
1610.61 | 1671.6 | 1714.3 | 2466.8 |
1630.75 | 1682.9 | 1734.5 | 2487.9 |
1640.17 | 1703.6 | 1757.4 | 2508.4 |
1635.47 | 1697.5 | 1754.0 | 2510.5 |
1645.89 | 1716.3 | 1754.3 | 2497.4 |
1647.84 | 1723.8 | 1759.8 | 2532.5 |
1638.35 | 1730.5 | 1755.5 | 2556.8 |
1629.93 | 1727.4 | 1758.1 | 2561.0 |
1621.49 | 1733.3 | 1757.5 | 2547.3 |
1624.74 | 1734.0 | 1763.5 | 2541.5 |
1627.63 | 1728.3 | 1762.8 | 2558.5 |
1631.99 | 1737.1 | 1768.9 | 2587.9 |
1621.18 | 1723.1 | 1778.1 | 2580.5 |
1613.42 | 1723.6 | 1780.1 | 2579.6 |
1604.95 | 1719.0 | 1767.7 | 2589.3 |
Answer key
1. We will calculate the standard deviation for each stock then compare them.
- Add up all of the numbers:
Sum for Apple = 247.6557.
Sum for Microsoft = 680.06.
Sum for Adobe = 882.17.
- Count the numbers of items in your sample. In this sample of each stock, there are 30 items.
- Divide the number you found in step 1 by the number you found in step 2.
The mean for Apple = 247.6557/30 = 8.255.
The mean for Microsoft = 680.06/30 = 22.67.
The mean for Apple = 882.17/30 = 29.41.
- Subtract the mean of each stock from each value of this stock and square the difference.
Apple | stock-mean for apple | squared difference for apple | Microsoft | stock-mean for Microsoft | squared difference for Microsoft | Adobe | stock-mean for Adobe | squared difference for Adobe |
8.881429 | 0.6264 | 0.39 | 22.82 | 0.15 | 0.02 | 28.72 | -0.69 | 0.48 |
8.808572 | 0.5536 | 0.31 | 22.76 | 0.09 | 0.01 | 29.00 | -0.41 | 0.17 |
8.571428 | 0.3164 | 0.10 | 22.50 | -0.17 | 0.03 | 29.47 | 0.06 | 0.00 |
8.531428 | 0.2764 | 0.08 | 22.13 | -0.54 | 0.29 | 29.84 | 0.43 | 0.18 |
8.365714 | 0.1107 | 0.01 | 22.04 | -0.63 | 0.40 | 28.82 | -0.59 | 0.35 |
8.680000 | 0.4250 | 0.18 | 22.11 | -0.56 | 0.31 | 27.85 | -1.56 | 2.43 |
8.462857 | 0.2079 | 0.04 | 21.92 | -0.75 | 0.56 | 27.99 | -1.42 | 2.02 |
8.142858 | -0.1121 | 0.01 | 21.71 | -0.96 | 0.92 | 28.84 | -0.57 | 0.32 |
8.332857 | 0.0779 | 0.01 | 21.51 | -1.16 | 1.35 | 28.98 | -0.43 | 0.18 |
8.230000 | -0.0250 | 0.00 | 21.88 | -0.79 | 0.62 | 28.57 | -0.84 | 0.71 |
8.482857 | 0.2279 | 0.05 | 22.07 | -0.60 | 0.36 | 28.96 | -0.45 | 0.20 |
8.222857 | -0.0321 | 0.00 | 22.10 | -0.57 | 0.32 | 29.12 | -0.29 | 0.08 |
8.171429 | -0.0836 | 0.01 | 22.55 | -0.12 | 0.01 | 28.78 | -0.63 | 0.40 |
8.210000 | -0.0450 | 0.00 | 22.56 | -0.11 | 0.01 | 29.53 | 0.12 | 0.01 |
8.265715 | 0.0107 | 0.00 | 23.08 | 0.41 | 0.17 | 29.88 | 0.47 | 0.22 |
8.511429 | 0.2564 | 0.07 | 22.88 | 0.21 | 0.04 | 30.79 | 1.38 | 1.90 |
8.404285 | 0.1493 | 0.02 | 22.50 | -0.17 | 0.03 | 30.60 | 1.19 | 1.42 |
8.427143 | 0.1721 | 0.03 | 22.82 | 0.15 | 0.02 | 30.69 | 1.28 | 1.64 |
8.204286 | -0.0507 | 0.00 | 22.86 | 0.19 | 0.04 | 29.94 | 0.53 | 0.28 |
8.002857 | -0.2521 | 0.06 | 23.16 | 0.49 | 0.24 | 30.06 | 0.65 | 0.42 |
8.424286 | 0.1693 | 0.03 | 23.47 | 0.80 | 0.64 | 30.40 | 0.99 | 0.98 |
8.181429 | -0.0736 | 0.01 | 23.30 | 0.63 | 0.40 | 30.36 | 0.95 | 0.90 |
8.278571 | 0.0236 | 0.00 | 23.70 | 1.03 | 1.06 | 30.64 | 1.23 | 1.51 |
8.142858 | -0.1121 | 0.01 | 23.35 | 0.68 | 0.46 | 29.86 | 0.45 | 0.20 |
7.967143 | -0.2879 | 0.08 | 23.48 | 0.81 | 0.66 | 29.59 | 0.18 | 0.03 |
7.914286 | -0.3407 | 0.12 | 23.30 | 0.63 | 0.40 | 29.42 | 0.01 | 0.00 |
7.857143 | -0.3979 | 0.16 | 23.50 | 0.83 | 0.69 | 29.26 | -0.15 | 0.02 |
7.950000 | -0.3050 | 0.09 | 23.10 | 0.43 | 0.18 | 29.55 | 0.14 | 0.02 |
7.565714 | -0.6893 | 0.48 | 22.64 | -0.03 | 0.00 | 28.56 | -0.85 | 0.72 |
7.464286 | -0.7907 | 0.63 | 22.26 | -0.41 | 0.17 | 28.10 | -1.31 | 1.72 |
- Add up all of the squared differences you found in Step 4 for each stock.
Sum of squared differences for Apple = 2.98.
Sum of squared differences for Microsoft = 10.41.
Sum of squared differences for Adobe = 19.51.
- Divide the number you get in step 5 by sample size-1 to get the variance. We have 30 numbers, so the sample size is 30.
The variance of Apple closing price = 2.98/(30-1) = 0.10 USD^2.
The variance of Microsoft closing price = 10.41/(30-1) = 0.36 USD^2.
The variance of Adobe closing price = 19.51/(30-1) = 0.67 USD^2.
- Take the square root of the variance to get the standard deviation.
The standard deviation of Apple = √0.10 = 0.32 USD.
The standard deviation of Microsoft = √0.36 = 0.60 USD.
The standard deviation of Adobe = √0.67 = 0.82 USD.
The Apple stock closing price has the least standard deviation. We can see that if we plot the data as a dot plot.
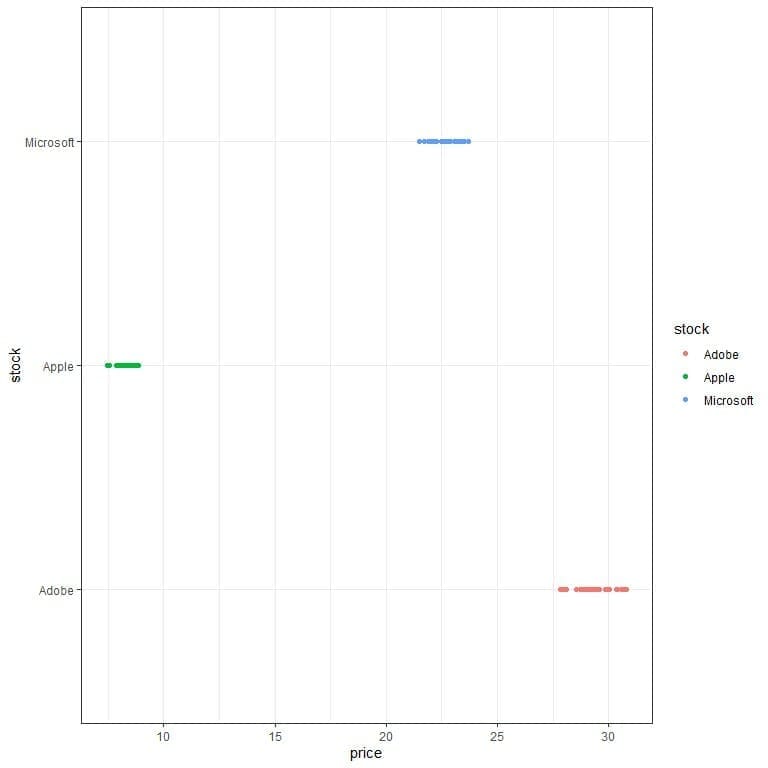 We see that the Apple prices are less scattered than Adobe or Microsoft prices.
We see that the Apple prices are less scattered than Adobe or Microsoft prices.
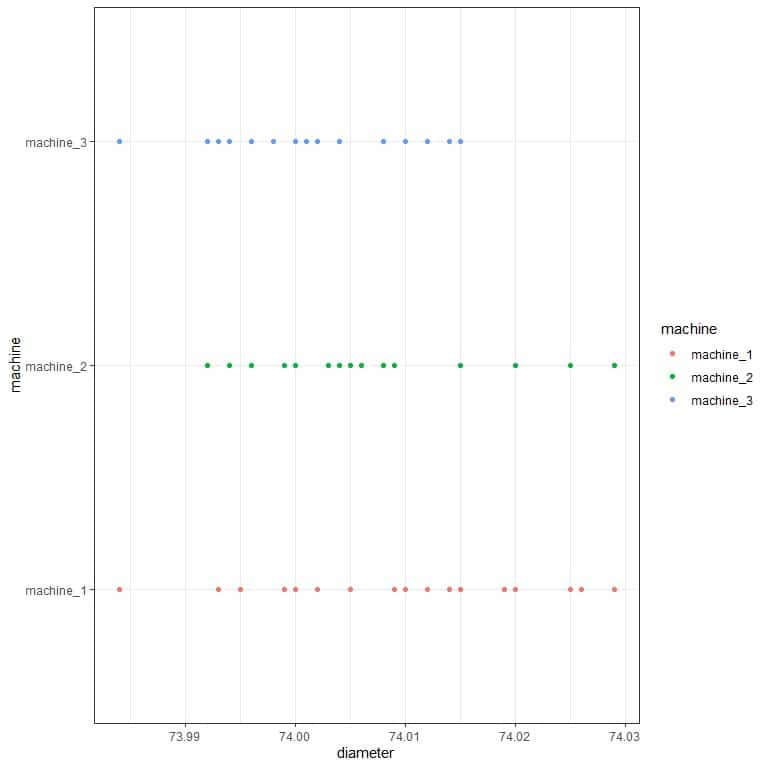
2. After doing similar calculations of question 1, we get the following table for each machine’s standard deviation.
machine | standard deviation |
machine_1 | 0.012 |
machine_2 | 0.010 |
machine_3 | 0.008 |
Machine_3 has the least standard deviation, and so it is more precise than the other 2 machines. We can see that if we plot the data as a dot plot.
3. Red dots are males (more dispersed), and blue dots are females.
4. Individuals with cv events have a lower standard deviation, so they are the blue dots.
5. After doing similar calculations of question 1, we get the following table for each stock’s standard deviation.
stock | standard deviation |
CAC | 21.166 |
DAX | 12.353 |
FTSE | 48.865 |
SMI | 22.499 |
The FTSE has the most standard deviation, and so it is riskier than the other 3 stocks. We can see that if we plot the data as a dot plot.